Mixed Models Part 1
Let's suppose we have a collection of data. It looks like this.
> head(df_test) y x Group 1 3.361500 56.76933 4 2 2.779182 53.85903 2 3 1.183500 23.78973 1 4 2.475000 61.04853 11 5 3.847500 86.93463 1 6 1.665000 25.19943 3 >

> ggplot(df_test, aes(x = Group, y = x)) + geom_boxplot() + geom_jitter(width = 0.25, size = 0.5)

print(df_test %>% group_by(Group) %>% count(), n = Inf) # A tibble: 21 × 2 # Groups: Group [21] Group n <fct> <int> 1 1 368 2 2 40 3 3 53 4 4 65 5 5 4 6 6 15 7 7 5 8 8 8 9 9 21 10 10 48 11 11 91 12 12 90 13 13 7 14 14 18 15 15 21 16 16 80 17 17 9 18 18 47 19 19 5 20 20 2 21 21 3 >
Do differences in data collected from various groups affect predictions of y from x?
Fixed Effect Models
Intercept Only Model
We can write this model more compactly as
\[y \sim N({\beta _0},{\sigma ^2})\]
That is, we are assuming that y is normally distributed around a constant mean.
This model is not very interesting. It estimates all y values with a
single value, the mean of the y data.
lm1 <- lm(y ~ 1, df_test)
|
term |
estimate |
std.error |
statistic |
p.value |
Significance |
|
(Intercept) |
3.110914914 |
0.033022011 |
94.20731236 |
0 |
*** |
A Linear Model
A more interesting model is to estimate y from x:
\[{y_i} = {\beta _0} + {\beta _1}{x_i} + {\varepsilon _i}\]
or in R,
> lm2 <- lm(y ~ x, df_test) > summary(lm2)$r.squared [1] 0.9216033 >
|
term |
estimate |
std.error |
statistic |
p.value |
Significance |
|
(Intercept) |
0.429480279 |
0.026427797 |
16.2510812 |
7.26E-53 |
*** |
|
x |
0.046343568 |
0.000427859 |
108.3149471 |
0 |
*** |
This model fits the data as a single line with intercept
given by ${\beta _0}$
That is, we assume that the data is normally distributed
with mean
Despite
the simplicity of the model, the R-squared value shows a good fit. The small
p-values indicate that the slope and intercept are significantly different from
zero.
ggplot(df_test) + geom_point(aes(x = x, y = y)) + geom_abline(intercept = coef(lm2)[1], slope = coef(lm2)[2])


The model above is called a “pooled” model by Gelman and Hill[i]. In the pooled model, group indicators such as Group are not included, and all data points are treated the same.
Does Group Affect the Intercept?
In contrast to the pooling the data, we can treat the data coming from a particular Group as a group. In this model, we treat each group separately. The group data influences the intercept of the group's regression line. Each of the groups will have its own intercept but will share a constant slope.
We model
the data as
\[\begin{array}{l}{y_i} = {\beta _{0j}} + {\beta _1}{x_i} + {\varepsilon _i}\\y \sim N({\beta _0}_j + {\beta _1}x,{\sigma ^2})\end{array}\]
> lm3 <- lm(y ~ x + Group, df_test) > summary(lm3)$r.squared [1] 0.9382607 >
|
term |
estimate |
std.error |
statistic |
p.value |
Significance |
|
(Intercept) |
0.360332077 |
0.027405965 |
13.14794332 |
1.78E-36 |
*** |
|
x |
0.047131182 |
0.000435566 |
108.2066739 |
0 |
*** |
|
Group2 |
-0.07538652 |
0.044281162 |
-1.702451264 |
0.088988577 |
. |
|
Group3 |
0.066682535 |
0.038890202 |
1.714635865 |
0.086728812 |
. |
|
Group4 |
0.064706621 |
0.035322174 |
1.83189806 |
0.067270603 |
. |
|
Group5 |
0.41749091 |
0.132207688 |
3.157841396 |
0.001638125 |
** |
|
Group6 |
0.482346602 |
0.070488133 |
6.842947662 |
1.37E-11 |
*** |
|
Group7 |
0.018043288 |
0.11812715 |
0.152744632 |
0.878631169 |
|
|
Group8 |
0.294320063 |
0.093729708 |
3.140093677 |
0.001739619 |
** |
|
Group9 |
-0.191411538 |
0.060235494 |
-3.177720059 |
0.001530941 |
** |
|
Group10 |
-0.015922307 |
0.040954613 |
-0.388779324 |
0.697524021 |
|
|
Group11 |
-0.161850618 |
0.031305195 |
-5.170088195 |
2.84E-07 |
*** |
|
Group12 |
0.281433594 |
0.030887334 |
9.111618311 |
4.48E-19 |
*** |
|
Group13 |
0.140925663 |
0.100076771 |
1.408175558 |
0.159396886 |
|
|
Group14 |
-0.311566742 |
0.063307379 |
-4.921491717 |
1.01E-06 |
*** |
|
Group15 |
0.103031195 |
0.058911077 |
1.74892738 |
0.080617274 |
. |
|
Group16 |
0.051262508 |
0.032700559 |
1.567634019 |
0.117290043 |
|
|
Group17 |
-0.148061746 |
0.088630367 |
-1.670553236 |
0.095129913 |
. |
|
Group18 |
-0.004371314 |
0.041148058 |
-0.106233781 |
0.915418655 |
|
|
Group19 |
0.026960639 |
0.118274662 |
0.227949403 |
0.819733223 |
|
|
Group20 |
0.083024504 |
0.185934553 |
0.446525415 |
0.65531661 |
|
|
Group21 |
0.426608271 |
0.152241561 |
2.802180089 |
0.005176093 |
** |
Group1’s intercept is shown in the results as “(Intercept)”. The values for the other groups are contrasts to Group1. To get the intercept for the other groups, add the contrast to Group1’s intercept. For example, Group2’s intercept is 0.360332077 + (-0.07538652) = 0.284945557. All Groups have same slope, shown in the table as x.
With this
model, we have a single slope and 21 intercepts, one for each group. Plotting the
individual groups shows that the intercept varies with group.

Do Groups Affect the Slope?
We can
examine the effects of the groups on the slopes of the individual fits by
including coefficients for individual slopes. The slightly more complicated
model is,
\[\begin{array}{l}{y_i} = {\beta _{0j}} + {\beta _{1j}}{x_i} + {\varepsilon _i}\\y \sim N({\beta _0}_j + {\beta _{1j}}x,{\sigma ^2})\\\end{array}\]
${\beta _{1j}}$ represents the slope term for group j, i.e. the slope represented by x is conditioned by the group.
> lm4 <- lm(y ~ x + Group + Group:x, df_test) > summary(lm4)$r.squared [1] 0.9420782 >
${\beta _{1j}}$ represents the slope
term for group j. In R,
Like the
preceding model, R returns estimates of the contrasts of the intercepts and in
this case also contrasts of the slopes. The intercept and slope for Group1, the
reference level, are “(Intercept)” and “x” respectively.
|
term |
estimate |
std.error |
statistic |
p.value |
Significance |
|
(Intercept) |
0.327341057 |
0.035265421 |
9.282210427 |
1.08E-19 |
*** |
|
x |
0.047736145 |
0.000598329 |
79.78237403 |
0 |
*** |
|
Group2 |
-0.160763278 |
0.182865882 |
-0.879132162 |
0.379550074 |
|
|
Group3 |
0.436566802 |
0.112747557 |
3.872073273 |
0.000115236 |
*** |
|
Group4 |
-0.048725662 |
0.12217049 |
-0.39883332 |
0.690104905 |
|
|
Group5 |
0.772420727 |
0.210121883 |
3.676060377 |
0.000250019 |
*** |
|
Group6 |
0.818985189 |
0.134193341 |
6.103024041 |
1.51E-09 |
*** |
|
Group7 |
0.543263921 |
0.942664681 |
0.576306646 |
0.5645433 |
|
|
Group8 |
0.301480732 |
0.250073417 |
1.205568889 |
0.228281442 |
|
|
Group9 |
-0.493229407 |
0.12981909 |
-3.799359604 |
0.000154218 |
*** |
|
Group10 |
-0.04718856 |
0.175264044 |
-0.269242677 |
0.787800917 |
|
|
Group11 |
-0.314246327 |
0.112618026 |
-2.790373248 |
0.005369266 |
** |
|
Group12 |
0.527963451 |
0.087878654 |
6.007869128 |
2.67E-09 |
*** |
|
Group13 |
-0.297769109 |
0.303638702 |
-0.980669153 |
0.327003507 |
|
|
Group14 |
6.652037742 |
7.897121744 |
0.842336988 |
0.399809588 |
|
|
Group15 |
-1.055984376 |
0.646956991 |
-1.632232732 |
0.102959097 |
|
|
Group16 |
0.138299803 |
0.110239818 |
1.254535842 |
0.209953293 |
|
|
Group17 |
-0.6357577 |
0.466520362 |
-1.362765169 |
0.173276776 |
|
|
Group18 |
0.116008531 |
0.176642979 |
0.656740117 |
0.51150576 |
|
|
Group19 |
0.374947709 |
0.614983092 |
0.609687833 |
0.54221319 |
|
|
Group20 |
1.20435612 |
1.061705537 |
1.134359837 |
0.256927397 |
|
|
Group21 |
4.987221872 |
1.743917693 |
2.859780535 |
0.004331392 |
** |
|
x:Group2 |
0.001050166 |
0.002516176 |
0.417365786 |
0.676504392 |
|
|
x:Group3 |
-0.008554796 |
0.002460093 |
-3.477427521 |
0.000529001 |
*** |
|
x:Group4 |
0.001903607 |
0.002019025 |
0.942834988 |
0.346003012 |
|
|
x:Group5 |
-0.010787213 |
0.005177655 |
-2.083416742 |
0.037477885 |
* |
|
x:Group6 |
-0.014218907 |
0.005022958 |
-2.83078363 |
0.004740559 |
** |
|
x:Group7 |
-0.008431415 |
0.014878328 |
-0.566691007 |
0.571056871 |
|
|
x:Group8 |
-0.000159151 |
0.004020386 |
-0.03958611 |
0.968431349 |
|
|
x:Group9 |
0.012845941 |
0.004526545 |
2.837913174 |
0.004636831 |
** |
|
x:Group10 |
0.000287811 |
0.002404708 |
0.119686302 |
0.904756746 |
|
|
x:Group11 |
0.002098228 |
0.001623657 |
1.292285511 |
0.19656991 |
|
|
x:Group12 |
-0.00425254 |
0.001426503 |
-2.981094186 |
0.002944823 |
** |
|
x:Group13 |
0.00735169 |
0.004853974 |
1.514571391 |
0.130210828 |
|
|
x:Group14 |
-0.131278034 |
0.148891426 |
-0.881703112 |
0.378158539 |
|
|
x:Group15 |
0.024393641 |
0.013509973 |
1.8056025 |
0.071294263 |
. |
|
x:Group16 |
-0.001430034 |
0.00164576 |
-0.868920355 |
0.385108328 |
|
|
x:Group17 |
0.007218412 |
0.006896262 |
1.04671371 |
0.295495653 |
|
|
x:Group18 |
-0.001860404 |
0.002500385 |
-0.744046906 |
0.457030552 |
|
|
x:Group19 |
-0.005075435 |
0.008580858 |
-0.591483395 |
0.554336117 |
|
|
x:Group20 |
-0.020374834 |
0.019000852 |
-1.072311629 |
0.283850132 |
|
|
x:Group21 |
-0.06229649 |
0.023678667 |
-2.630911986 |
0.008652347 |
** |
The intercept for Group2 is 0.327341057+ (0.160763278) = 0.166577779. x:Group2 represents the slope contrast for Group2. The slope is given by x + x:Group2, 0.047736145 + 0.001050166 = 0.049836477.
Plotting
the slopes shows some dramatic changes in the slopes for a few for the group. In
particular, Group 14’s slope is in a different direction from that of the other
groups. Notice that the regression line for Group14 is different from
the rest. Most of the slopes have slight shifts from Group1.
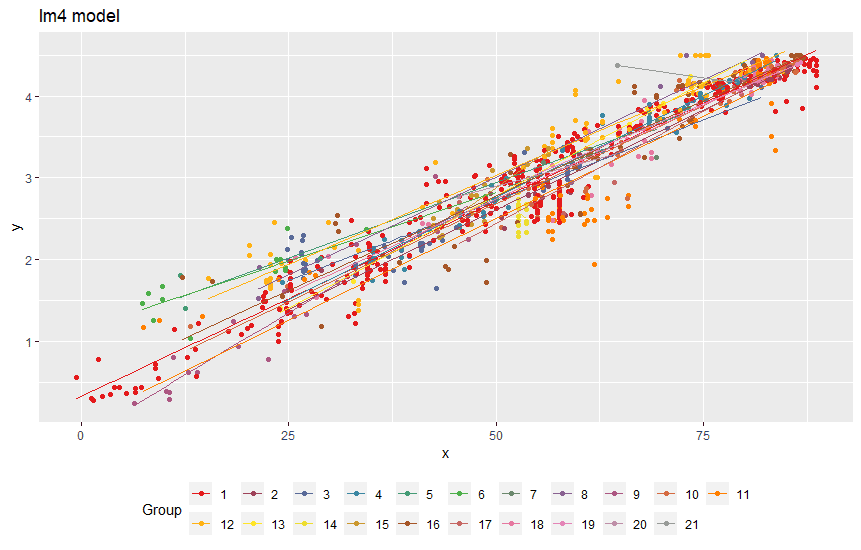
Does Adding Groups Improve the Models?
We have looked at four linear models:
\[\begin{array}{l}lm1:y \sim N({\beta _0},{\sigma ^2})\\lm2:y \sim N({\beta _0} + {\beta _1}x,{\sigma ^2})\\lm3:y \sim N({\beta _{0j}} + {\beta _1}x,{\sigma ^2})\\lm4:y \sim N({\beta _{0j}} + {\beta _{1j}}x,{\sigma ^2})\end{array}\]
The models
are nested, i.e. the independent variables of the simpler model are a subset of
the more complex model. We will assume a Null Hypothesis that the simple model is better,
and we reject the null hypothesis if the p-value is small. In our case, less than 0.001.
> anova(lm1, lm2, lm3, lm4) Analysis of Variance Table Model 1: y ~ 1 Model 2: y ~ x Model 3: y ~ x + Group Model 4: y ~ x + Group + Group:x Res.Df RSS Df Sum of Sq F Pr(>F) 1 999 1089.36 2 998 85.40 1 1003.96 15242.9063 < 2.2e-16 *** 3 978 67.26 20 18.15 13.7753 < 2.2e-16 *** 4 958 63.10 20 4.16 3.1571 3.849e-06 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 >
Given the
small p-values we can safely reject the null hypothesis. Despite increased
degrees of freedom, the more complex models are preferred over the simpler
ones.
Another common method of comparing models is the log likelihood ratio test. In this test, the log likelihood ratios of nested models are compared sequentially, and a chi squared test of significance is performed. We reject the null hypothesis if the resulting p-values are small.
> library(lmtest) > lrtest(lm1, lm2, lm3, lm4) Likelihood ratio test Model 1: y ~ 1 Model 2: y ~ x Model 3: y ~ x + Group Model 4: y ~ x + Group + Group:x #Df LogLik Df Chisq Pr(>Chisq) 1 2 -1461.73 2 3 -188.75 1 2545.974 < 2.2e-16 *** 3 23 -69.32 20 238.861 < 2.2e-16 *** 4 43 -37.40 20 63.828 1.791e-06 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 >
The small
p-values indicate that we can safely reject the null hypothesis that simpler
models are preferred.
[i] Gelman, A., & Hill, J. (2007). Data Analysis Using Regression and Multilevel/Hierarchical Models. New York: Cambridge University Press.


Comments
Post a Comment